Increasing Delivery Pipeline Observability
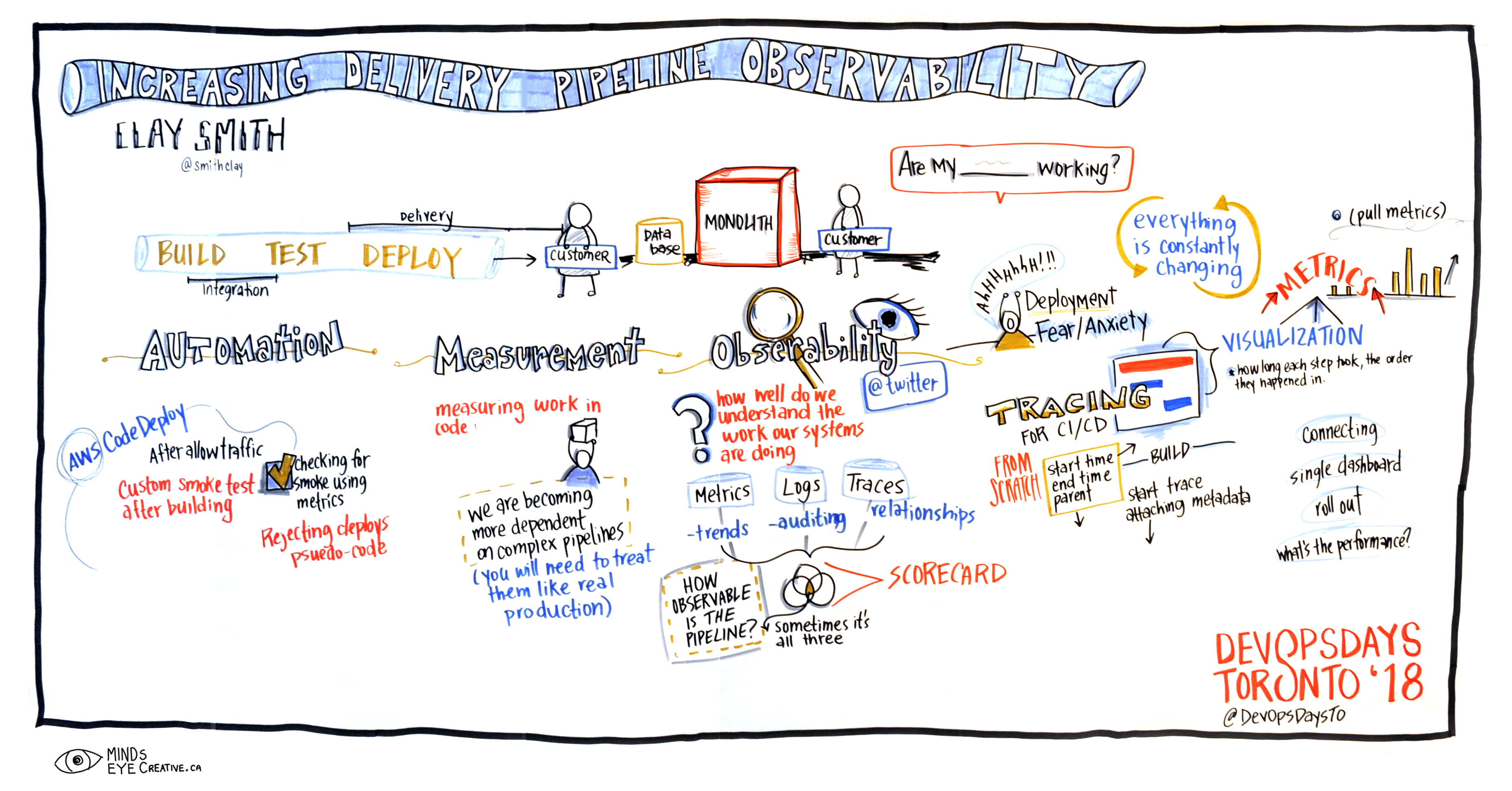
Software engineering teams are becoming more sophisticated about how they deploy software to production. This is reflected in the increasing complexity of software delivery pipelines that contain dozens of stages and advanced rollout strategies that are designed to ensure changes are quickly and safely rolled out to production with minimal human intervention.
Despite the importance of pipelines, measuring their performance and effectiveness is often an afterthought with few (if any) metrics, hard-to-understand logs, and (maybe) a neglected dashboard. This talk explores how to adapt observability best practices learned from operating microservice architectures and apply them to understand and improve delivery pipelines.
We’ll discuss how to instrument pipelines in popular tools like Jenkins to create traces and review useful metrics to track when understanding overall pipeline performance—from first commit to full rollout in production. Using real data from the instrumentation of a production pipeline, we’ll share how we used data collected to optimize performance by understanding where bottlenecks are.
Audience members will learn about observability practices by applying them to pipelines, and examples of it helps optimize a real-world system. The goal of this talk is to share new techniques—particularly pipeline instrumentation that creates traces for debugging—to help teams that are building or using pipelines improve them and make them faster and more resilient.
Speaker

Clay Smith
Clay Smith is a Developer Advocate at New Relic in San Francisco. He previously was a Senior Software Engineer at PagerDuty and focused on building APIs and web applications at startups and large enterprises.
Platinum Sponsors

Gold Sponsors











Silver Sponsors










Lanyard Sponsors
Happy Hour Sponsors
Join as Happy Hour Sponsor!Lunch Sponsors
Join as Lunch Sponsor!Bronze Sponsors
Join as Bronze Sponsor!

